前言
第八讲介绍了当 goroutine 运行时间过长会被抢占的情况。这一讲继续看 goroutine 执行系统调用时间过长的抢占。
系统调用时间过长的抢占
看下面的示例:
1func longSyscall() {
2 timeout := syscall.NsecToTimeval(int64(5 * time.Second))
3 fds := make([]syscall.FdSet, 1)
4
5 if _, err := syscall.Select(0, &fds[0], nil, nil, &timeout); err != nil {
6 fmt.Println("Error:", err)
7 }
8
9 fmt.Println("Select returned after timeout")
10}
11
12func main() {
13 threads := runtime.GOMAXPROCS(0)
14 for i := 0; i < threads; i++ {
15 go longSyscall()
16 }
17
18 time.Sleep(8 * time.Second)
19}
longSyscall goroutine 执行一个 5s 的系统调用,在系统调用过程中,sysmon 会监控 longSyscall,发现执行系统调用过长,会对其抢占。
回到 sysmon 线程看它是怎么抢占系统调用时间过长的 goroutine 的。
1func sysmon() {
2 ...
3 idle := 0 // how many cycles in succession we had not wokeup somebody
4 delay := uint32(0)
5 ...
6
7 for {
8 if idle == 0 { // start with 20us sleep...
9 delay = 20
10 } else if idle > 50 { // start doubling the sleep after 1ms...
11 delay *= 2
12 }
13 if delay > 10*1000 { // up to 10ms
14 delay = 10 * 1000
15 }
16 usleep(delay)
17
18 ...
19 // retake P's blocked in syscalls
20 // and preempt long running G's
21 if retake(now) != 0 {
22 idle = 0
23 } else {
24 idle++
25 }
26 ...
27 }
28}
类似于运行时间过长的 goroutine,调用 retake 进行抢占:
1func retake(now int64) uint32 {
2 n := 0
3 lock(&allpLock)
4 for i := 0; i < len(allp); i++ {
5 pp := allp[i]
6 if pp == nil {
7 continue
8 }
9 pd := &pp.sysmontick
10 s := pp.status
11 sysretake := false
12
13 if s == _Prunning || s == _Psyscall { // goroutine 处于 _Prunning 或 _Psyscall 时会抢占
14 // Preempt G if it's running for too long.
15 t := int64(pp.schedtick)
16 if int64(pd.schedtick) != t {
17 pd.schedtick = uint32(t)
18 pd.schedwhen = now
19 } else if pd.schedwhen+forcePreemptNS <= now {
20 // 对于 _Prunning 或者 _Psyscall 运行时间过长的情况,都会进入 preemptone
21 // preemptone 我们在运行时间过长的抢占中介绍过,它主要设置了 goroutine 的标志位
22 // 对于处于系统调用的 goroutine,这么设置并不会抢占。因为线程一直处于系统调用状态
23 preemptone(pp)
24 // In case of syscall, preemptone() doesn't
25 // work, because there is no M wired to P.
26 sysretake = true
27 }
28 }
29
30 if s == _Psyscall {
31 // Retake P from syscall if it's there for more than 1 sysmon tick (at least 20us).
32 // P 处于系统调用之中,需要检查是否需要抢占
33 // syscalltick 用于记录系统调用的次数,在完成系统调用之后加 1
34 t := int64(pp.syscalltick)
35 if !sysretake && int64(pd.syscalltick) != t {
36 // pd.syscalltick != pp.syscalltick,说明已经不是上次观察到的系统调用了,
37 // 而是另外一次系统调用,需要重新记录 tick 和 when 值
38 pd.syscalltick = uint32(t)
39 pd.syscallwhen = now
40 continue
41 }
42
43 // On the one hand we don't want to retake Ps if there is no other work to do,
44 // but on the other hand we want to retake them eventually
45 // because they can prevent the sysmon thread from deep sleep.
46 // 如果满足下面三个条件的一个则执行抢占:
47 // 1. 线程绑定的本地队列中有可运行的 goroutine
48 // 2. 没有无所事事的 P(表示大家都挺忙的,那就不要执行系统调用那么长时间占资源了)
49 // 3. 执行系统调用时间超过 10ms 的
50 if runqempty(pp) && sched.nmspinning.Load()+sched.npidle.Load() > 0 && pd.syscallwhen+10*1000*1000 > now {
51 continue
52 }
53
54 // 下面是执行抢占的逻辑
55 unlock(&allpLock)
56 // Need to decrement number of idle locked M's
57 // (pretending that one more is running) before the CAS.
58 // Otherwise the M from which we retake can exit the syscall,
59 // increment nmidle and report deadlock.
60 incidlelocked(-1)
61 if atomic.Cas(&pp.status, s, _Pidle) { // 将 P 的状态更新为 _Pidle
62 n++ // 抢占次数 + 1
63 pp.syscalltick++ // 系统调用抢占次数 + 1
64 handoffp(pp) // handoffp 抢占
65 }
66 incidlelocked(1)
67 lock(&allpLock)
68 }
69 }
70 unlock(&allpLock)
71 return uint32(n)
72}
进入 handoffp:
1// Hands off P from syscall or locked M.
2// Always runs without a P, so write barriers are not allowed.
3//
4//go:nowritebarrierrec
5func handoffp(pp *p) {
6 // if it has local work, start it straight away
7 // 这里如果 P 的本地有工作(goroutine),或者全局有工作的话
8 // 将 P 和其它线程绑定,其它线程指的是不是执行系统调用的那个线程
9 // 执行系统调用的线程不需要 P 了,这时候把 P 释放出来,算是资源的合理利用,相比于线程,P 是有限的
10 if !runqempty(pp) || sched.runqsize != 0 {
11 startm(pp, false, false)
12 return
13 }
14
15 ...
16 // no local work, check that there are no spinning/idle M's,
17 // otherwise our help is not required
18 if sched.nmspinning.Load()+sched.npidle.Load() == 0 && sched.nmspinning.CompareAndSwap(0, 1) { // TODO: fast atomic
19 sched.needspinning.Store(0)
20 startm(pp, true, false)
21 return
22 }
23
24 ...
25 // 判断全局队列有没有工作要处理
26 if sched.runqsize != 0 {
27 unlock(&sched.lock)
28 startm(pp, false, false)
29 return
30 }
31
32 ...
33 // 如果都没有工作,那就把 P 放到全局空闲队列中
34 pidleput(pp, 0)
35 unlock(&sched.lock)
36}
可以看到抢占系统调用过长的 goroutine,这里抢占的意思是释放系统调用线程所绑定的 P,抢占的意思不是不让线程做系统调用,而是把 P 释放出来。(由于前面设置了这个 goroutine 的 stackguard0,类似于 运行时间过长 goroutine 的抢占 的流程还是会走一遍的)。
我们看一个示意图可以更直观清晰的了解这个过程:
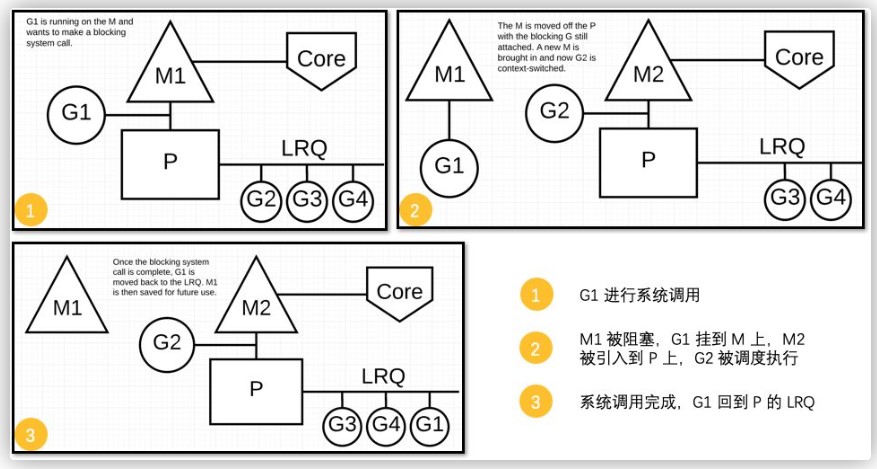
handoff 结束之后,增加抢占次数 n,retake 返回:
1func sysmon() {
2 ...
3 idle := 0 // how many cycles in succession we had not wokeup somebody
4 delay := uint32(0)
5 for {
6 if idle == 0 { // start with 20us sleep...
7 delay = 20 // 如果 idle == 0,表示 sysmon 需要打起精神来,要隔 20us 监控一次
8 } else if idle > 50 { // start doubling the sleep after 1ms...
9 delay *= 2 // 如果 idle 大于 50,表示循环了 50 次都没有抢占,sysmon 将加倍休眠,比较空,sysmon 也不浪费资源,先睡一会
10 }
11 if delay > 10*1000 { // up to 10ms
12 delay = 10 * 1000 // 当然,不能无限制睡下去。最大休眠时间设置成 10ms
13 }
14
15 if retake(now) != 0 {
16 idle = 0 // 有抢占,则 idle = 0,表示 sysmon 要忙起来
17 } else {
18 idle++ // 没有抢占,idle + 1
19 }
20 ...
21 }
22 ...
23}
小结
本讲介绍了系统调用时间过长引起的抢占。下一讲将继续介绍异步抢占。