前言
[译] kubernetes:kube-scheduler 调度器代码结构概述 介绍了 kube-scheduler 的代码结构。本文围绕代码结构,从源码角度出发,分析 kube-scheduler 的调度逻辑。
启动 kube-scheduler
kube-scheduler 使用 Cobra 框架初始化参数,配置和应用。
1// kubernetes/cmd/kube-scheduler/scheduler.go
2func main() {
3 // 启动 kube-scheduler 入口
4 command := app.NewSchedulerCommand()
5 ...
6}
7
8// kubernetes/cmd/kube-scheduler/app/server.go
9func NewSchedulerCommand(registryOptions ...Option) *cobra.Command {
10 // 创建 kube-scheduler 选项
11 opts := options.NewOptions()
12
13 cmd := &cobra.Command{
14 Use: "kube-scheduler",
15 ...
16 RunE: func(cmd *cobra.Command, args []string) error {
17 return runCommand(cmd, opts, registryOptions...)
18 },
19 ...
20 }
21 ...
22}
23
24// 运行 kube-scheduler
25func runCommand(cmd *cobra.Command, opts *options.Options, registryOptions ...Option) error {
26 ...
27 // 创建 kube-scheduler 配置 cc
28 // 创建 kube-scheduler 实例 sched
29 cc, sched, err := Setup(ctx, opts, registryOptions...)
30 if err != nil {
31 return err
32 }
33 ...
34 return Run(ctx, cc, sched)
35}
从启动命令来看,这里重点关注的是 Setup 函数。在该函数内,创建 kube-scheduler 配置 cc 和调度器实例 sched。
1func Setup(ctx context.Context, opts *options.Options, outOfTreeRegistryOptions ...Option) (*schedulerserverconfig.CompletedConfig, *scheduler.Scheduler, error) {
2 ...
3 // 验证选项
4 if errs := opts.Validate(); len(errs) > 0 {
5 return nil, nil, utilerrors.NewAggregate(errs)
6 }
7
8 // 根据选项创建配置 c
9 c, err := opts.Config(ctx)
10 if err != nil {
11 return nil, nil, err
12 }
13
14 // 补充配置为完整配置
15 cc := c.Complete()
16
17 // 外部注册插件
18 outOfTreeRegistry := make(runtime.Registry)
19 for _, option := range outOfTreeRegistryOptions {
20 if err := option(outOfTreeRegistry); err != nil {
21 return nil, nil, err
22 }
23 }
24
25 ...
26 // 创建调度器实例 sched
27 sched, err := scheduler.New(ctx,
28 cc.Client,
29 cc.InformerFactory,
30 cc.DynInformerFactory,
31 recorderFactory,
32 scheduler.WithComponentConfigVersion(cc.ComponentConfig.TypeMeta.APIVersion),
33 scheduler.WithKubeConfig(cc.KubeConfig),
34 scheduler.WithProfiles(cc.ComponentConfig.Profiles...),
35 scheduler.WithPercentageOfNodesToScore(cc.ComponentConfig.PercentageOfNodesToScore),
36 scheduler.WithFrameworkOutOfTreeRegistry(outOfTreeRegistry),
37 scheduler.WithPodMaxBackoffSeconds(cc.ComponentConfig.PodMaxBackoffSeconds),
38 scheduler.WithPodInitialBackoffSeconds(cc.ComponentConfig.PodInitialBackoffSeconds),
39 scheduler.WithPodMaxInUnschedulablePodsDuration(cc.PodMaxInUnschedulablePodsDuration),
40 scheduler.WithExtenders(cc.ComponentConfig.Extenders...),
41 scheduler.WithParallelism(cc.ComponentConfig.Parallelism),
42 scheduler.WithBuildFrameworkCapturer(func(profile kubeschedulerconfig.KubeSchedulerProfile) {
43 // Profiles are processed during Framework instantiation to set default plugins and configurations. Capturing them for logging
44 completedProfiles = append(completedProfiles, profile)
45 }),
46 )
47
48 ...
49 return &cc, sched, nil
50}
函数 scheduler.New 创建调度器实例 sched,进入函数内查看实例是如何创建的。
1func New(ctx context.Context,
2 client clientset.Interface,
3 informerFactory informers.SharedInformerFactory,
4 dynInformerFactory dynamicinformer.DynamicSharedInformerFactory,
5 recorderFactory profile.RecorderFactory,
6 opts ...Option) (*Scheduler, error) {
7 ...
8 // 注册内置插件
9 registry := frameworkplugins.NewInTreeRegistry()
10
11 // merge 内置插件和外部注册插件
12 if err := registry.Merge(options.frameworkOutOfTreeRegistry); err != nil {
13 return nil, err
14 }
15
16 // 注册指标
17 metrics.Register()
18
19 // 注册外部扩展器
20 extenders, err := buildExtenders(logger, options.extenders, options.profiles)
21 if err != nil {
22 return nil, fmt.Errorf("couldn't build extenders: %w", err)
23 }
24
25 // 实例化 podLister 负责监控 pod 变化
26 podLister := informerFactory.Core().V1().Pods().Lister()
27 // 实例化 nodeLister 负责监控 node 变化
28 nodeLister := informerFactory.Core().V1().Nodes().Lister()
29
30 // 创建 snapshot,snapshot 作为缓存存在
31 snapshot := internalcache.NewEmptySnapshot()
32
33 ...
34 // 创建 profiles,profiles 中存储的是调度器框架
35 profiles, err := profile.NewMap(ctx, options.profiles, registry, recorderFactory,
36 frameworkruntime.WithComponentConfigVersion(options.componentConfigVersion),
37 frameworkruntime.WithClientSet(client),
38 frameworkruntime.WithKubeConfig(options.kubeConfig),
39 frameworkruntime.WithInformerFactory(informerFactory),
40 frameworkruntime.WithSnapshotSharedLister(snapshot),
41 frameworkruntime.WithCaptureProfile(frameworkruntime.CaptureProfile(options.frameworkCapturer)),
42 frameworkruntime.WithParallelism(int(options.parallelism)),
43 frameworkruntime.WithExtenders(extenders),
44 frameworkruntime.WithMetricsRecorder(metricsRecorder),
45 )
46
47 // 创建 preEnqueuePlugin 插件
48 preEnqueuePluginMap := make(map[string][]framework.PreEnqueuePlugin)
49 ...
50
51 // 创建优先级队列 podQueue
52 podQueue := internalqueue.NewSchedulingQueue(
53 profiles[options.profiles[0].SchedulerName].QueueSortFunc(),
54 informerFactory,
55 internalqueue.WithPodInitialBackoffDuration(time.Duration(options.podInitialBackoffSeconds)*time.Second),
56 internalqueue.WithPodMaxBackoffDuration(time.Duration(options.podMaxBackoffSeconds)*time.Second),
57 internalqueue.WithPodLister(podLister),
58 internalqueue.WithPodMaxInUnschedulablePodsDuration(options.podMaxInUnschedulablePodsDuration),
59 internalqueue.WithPreEnqueuePluginMap(preEnqueuePluginMap),
60 internalqueue.WithQueueingHintMapPerProfile(queueingHintsPerProfile),
61 internalqueue.WithPluginMetricsSamplePercent(pluginMetricsSamplePercent),
62 internalqueue.WithMetricsRecorder(*metricsRecorder),
63 )
64
65 ...
66 // 创建调度器缓存
67 schedulerCache := internalcache.New(ctx, durationToExpireAssumedPod)
68 ...
69
70 // 实例化调度器
71 sched := &Scheduler{
72 Cache: schedulerCache,
73 client: client,
74 nodeInfoSnapshot: snapshot,
75 percentageOfNodesToScore: options.percentageOfNodesToScore,
76 Extenders: extenders,
77 StopEverything: stopEverything,
78 SchedulingQueue: podQueue,
79 Profiles: profiles,
80 logger: logger,
81 }
82
83 // 将队列的 Pop 方法赋值给 sched.NextPod
84 sched.NextPod = podQueue.Pop
85 ...
86
87 // 添加 Event 回调 handler
88 if err = addAllEventHandlers(sched, informerFactory, dynInformerFactory, unionedGVKs(queueingHintsPerProfile)); err != nil {
89 return nil, fmt.Errorf("adding event handlers: %w", err)
90 }
91
92 return sched, nil
93}
scheduler.New 创建了 snapshot, eventHandler, profiles(framework) 和 cache 等对象,结合着调度框架将它们关联起来会更清晰。
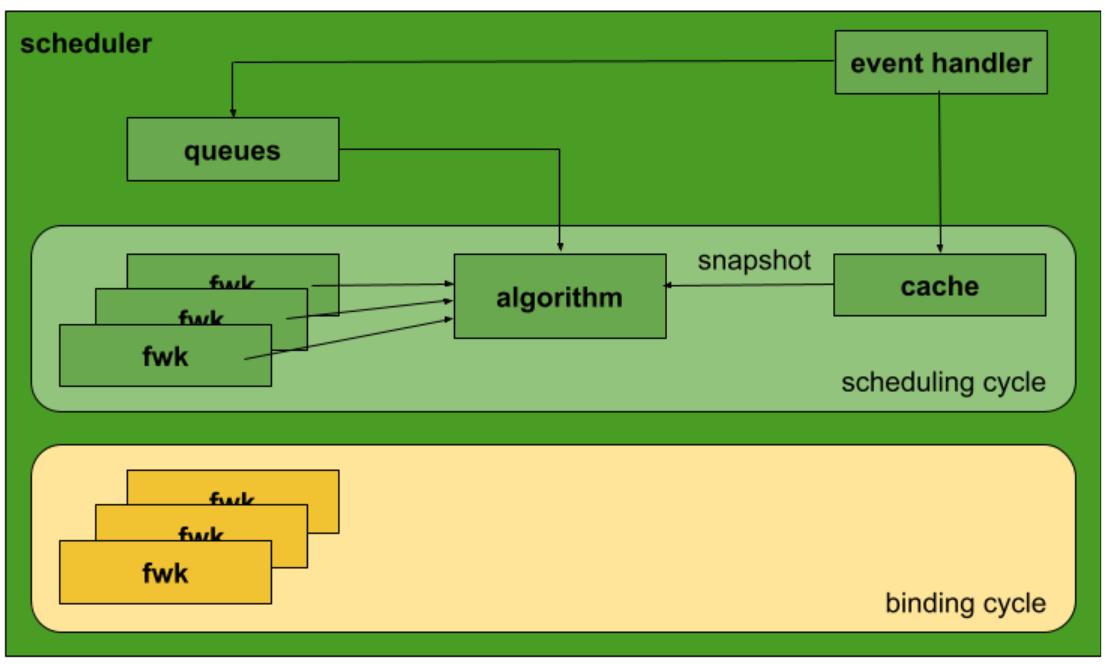
运行 kube-scheduler
创建完各个对象之后,接下来运行 kube-scheduler 将各个对象关联起来运行。
1func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler) error {
2 ...
3 // 选举 leader
4 waitingForLeader := make(chan struct{})
5 isLeader := func() bool {
6 select {
7 case _, ok := <-waitingForLeader:
8 // if channel is closed, we are leading
9 return !ok
10 default:
11 // channel is open, we are waiting for a leader
12 return false
13 }
14 }
15
16 ...
17 // 运行 informer
18 startInformersAndWaitForSync := func(ctx context.Context) {
19 // Start all informers.
20 cc.InformerFactory.Start(ctx.Done())
21 // DynInformerFactory can be nil in tests.
22 if cc.DynInformerFactory != nil {
23 cc.DynInformerFactory.Start(ctx.Done())
24 }
25
26 // Wait for all caches to sync before scheduling.
27 cc.InformerFactory.WaitForCacheSync(ctx.Done())
28 // DynInformerFactory can be nil in tests.
29 if cc.DynInformerFactory != nil {
30 cc.DynInformerFactory.WaitForCacheSync(ctx.Done())
31 }
32
33 // Wait for all handlers to sync (all items in the initial list delivered) before scheduling.
34 if err := sched.WaitForHandlersSync(ctx); err != nil {
35 logger.Error(err, "waiting for handlers to sync")
36 }
37
38 logger.V(3).Info("Handlers synced")
39 }
40 if !cc.ComponentConfig.DelayCacheUntilActive || cc.LeaderElection == nil {
41 startInformersAndWaitForSync(ctx)
42 }
43
44 // leader 节点运行调度逻辑,暂略
45 if cc.LeaderElection != nil {
46 ...
47 }
48
49 close(waitingForLeader)
50 sched.Run(ctx)
51 return fmt.Errorf("finished without leader elect")
52}
Run 函数内包含三部分处理:
- 选举 leader 节点。如果是单节点,则跳过选举。
- 运行 informer,负责监控 pod 和 node 变化。
- 运行调度器
进入 sched.Run 查看调度器是如何运行的。
1func (sched *Scheduler) Run(ctx context.Context) {
2 ...
3 // 从队列中去需要调度的 pod
4 sched.SchedulingQueue.Run(logger)
5
6 // 调度 pod
7 go wait.UntilWithContext(ctx, sched.scheduleOne, 0)
8
9 <-ctx.Done()
10 ...
11}
sched.Run 主要做了两件事。从优先级队列中取用于调度的 pod,然后通过 sched.scheduleOne 调度该 pod。
首先,看取调度 pod 的过程,如下。
1func (p *PriorityQueue) Run(logger klog.Logger) {
2 go wait.Until(func() {
3 p.flushBackoffQCompleted(logger)
4 }, 1.0*time.Second, p.stop)
5 go wait.Until(func() {
6 p.flushUnschedulablePodsLeftover(logger)
7 }, 30*time.Second, p.stop)
8}
优先级队列由 ActiveQ,BackoffQ 和 UnschedulableQ 组成,其逻辑关系如下。
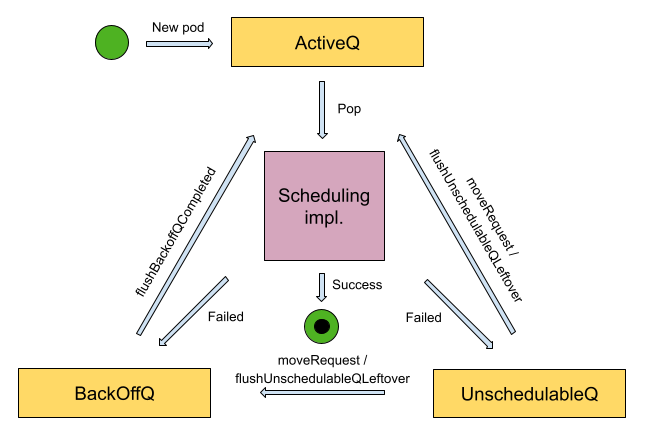
在 PriorityQueue.Run 中启动两个 goroutine 分别运行 p.flushBackoffQCompleted 和 p.flushUnschedulablePodsLeftover 方法。p.flushBackoffQCompleted 将处于 BackOffQ 的 pod 移到 ActiveQ。p.flushUnschedulablePodsLeftover 将 UnschedulableQ 的 pod 移到 ActiveQ 或者 BackOffQ。详细取调度 pod 的逻辑可查看 kube-scheduler 调度队列。
接着,进入 sched.scheduleOne 查看 pod 是怎么调度的。
1func (sched *Scheduler) scheduleOne(ctx context.Context) {
2 ...
3 // 获取需要调度的 pod
4 podInfo, err := sched.NextPod(logger)
5
6 ...
7 // 进入调度循环调度 pod
8 scheduleResult, assumedPodInfo, status := sched.schedulingCycle(schedulingCycleCtx, state, fwk, podInfo, start, podsToActivate)
9 if !status.IsSuccess() {
10 sched.FailureHandler(schedulingCycleCtx, fwk, assumedPodInfo, status, scheduleResult.nominatingInfo, start)
11 return
12 }
13
14 // 进入绑定循环绑定 pod
15 go func() {
16 ...
17 status := sched.bindingCycle(bindingCycleCtx, state, fwk, scheduleResult, assumedPodInfo, start, podsToActivate)
18 ...
19 }()
20}
sched.scheduleOne 主要包括三部分:获取需要调度的 pod,进入调度循环调度 pod 和进入绑定循环绑定 pod。其逻辑结构如下。
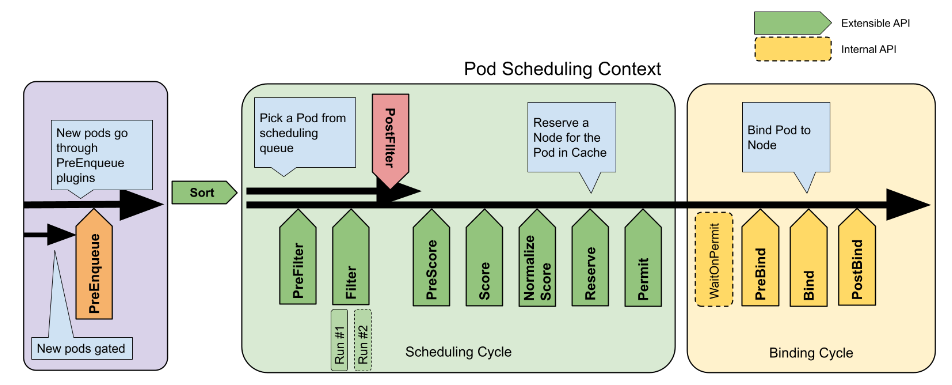
进一步,查看每一部分的源码。
sched.NextPod 获取需要调度的 pod
1func (p *PriorityQueue) Pop(logger klog.Logger) (*framework.QueuedPodInfo, error) {
2 ...
3 for p.activeQ.Len() == 0 {
4 if p.closed {
5 logger.V(2).Info("Scheduling queue is closed")
6 return nil, nil
7 }
8
9 // 如果 activeQ 没有 pod 的话,阻塞等待
10 p.cond.Wait()
11 }
12
13 // 从 activeQ 中取 pod
14 obj, err := p.activeQ.Pop()
15 if err != nil {
16 return nil, err
17 }
18 pInfo := obj.(*framework.QueuedPodInfo)
19 ...
20
21 return pInfo, nil
22}
sched.NextPod 的逻辑主要是看 activeQ 队列中有没有 pod,如果有的话,取 pod 调度。如果没有的话,阻塞等待,直到 activeQ 中有 pod。
sched.schedulingCycle 调度 pod
1func (sched *Scheduler) schedulingCycle(
2 ctx context.Context,
3 state *framework.CycleState,
4 fwk framework.Framework,
5 podInfo *framework.QueuedPodInfo,
6 start time.Time,
7 podsToActivate *framework.PodsToActivate,
8) (ScheduleResult, *framework.QueuedPodInfo, *framework.Status) {
9 ...
10 // 调度 Pod
11 scheduleResult, err := sched.SchedulePod(ctx, fwk, state, pod)
12 ...
13
14 assumedPodInfo := podInfo.DeepCopy()
15 assumedPod := assumedPodInfo.Pod
16 err = sched.assume(logger, assumedPod, scheduleResult.SuggestedHost)
17 ...
18
19 // 运行 Reserve 插件的 Reserve 方法
20 if sts := fwk.RunReservePluginsReserve(ctx, state, assumedPod, scheduleResult.SuggestedHost); !sts.IsSuccess() {
21 ...
22 }
23
24 // 运行 Permit 插件
25 runPermitStatus := fwk.RunPermitPlugins(ctx, state, assumedPod, scheduleResult.SuggestedHost)
26 if !runPermitStatus.IsWait() && !runPermitStatus.IsSuccess() {
27 ...
28 }
29
30 ...
31 return scheduleResult, assumedPodInfo, nil
32}
sched.schedulingCycle 包含几个步骤:sched.SchedulePod 调度 Pod,将调度的还未绑定的 Pod 作为 assumedPod 添加到缓存,运行 Reserve 插件和 Permit 插件。
首先,看 sched.SchedulePod 是怎么调度 Pod 的。
1func (sched *Scheduler) schedulePod(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (result ScheduleResult, err error) {
2 feasibleNodes, diagnosis, err := sched.findNodesThatFitPod(ctx, fwk, state, pod)
3 if err != nil {
4 return result, err
5 }
6 ...
7}
在 sched.SchedulePod 中,sched.findNodesThatFitPod 为 Pod 寻找合适的节点。
1// kubernetes/pkg/scheduler/schedule_one.go
2func (sched *Scheduler) findNodesThatFitPod(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) ([]*framework.NodeInfo, framework.Diagnosis, error) {
3 ...
4 // 从 snapshot 中取所有节点
5 allNodes, err := sched.nodeInfoSnapshot.NodeInfos().List()
6 if err != nil {
7 return nil, diagnosis, err
8 }
9
10 preRes, s := fwk.RunPreFilterPlugins(ctx, state, pod)
11 if !s.IsSuccess() {
12 ...
13 }
14
15 ...
16 // 寻找 pod 可调用的节点
17 feasibleNodes, err := sched.findNodesThatPassFilters(ctx, fwk, state, pod, &diagnosis, nodes)
18 ...
19}
20
21// kubernetes/pkg/scheduler/schedule_one.go
22func (sched *Scheduler) findNodesThatPassFilters(
23 ctx context.Context,
24 fwk framework.Framework,
25 state *framework.CycleState,
26 pod *v1.Pod,
27 diagnosis *framework.Diagnosis,
28 nodes []*framework.NodeInfo) ([]*framework.NodeInfo, error) {
29 ...
30 checkNode := func(i int) {
31 ...
32 status := fwk.RunFilterPluginsWithNominatedPods(ctx, state, pod, nodeInfo)
33 }
34 ...
35}
36
37// kubernetes/pkg/scheduler/framework/runtime/framework.go
38func (f *frameworkImpl) RunFilterPluginsWithNominatedPods(ctx context.Context, state *framework.CycleState, pod *v1.Pod, info *framework.NodeInfo) *framework.Status {
39 ...
40 for i := 0; i < 2; i++ {
41 ...
42 // 运行 Filter 插件
43 status = f.RunFilterPlugins(ctx, stateToUse, pod, nodeInfoToUse)
44 if !status.IsSuccess() && !status.IsRejected() {
45 return status
46 }
47 }
48
49 return status
50}
sched.findNodesThatFitPod 运行 Filter 插件获取可用的节点 feasibleNodes。接着,如果可用的节点只有一个,则返回调度结果。如果有多个节点则运行 priority 插件寻找最合适的节点作为调度节点。逻辑如下。
1func (sched *Scheduler) schedulePod(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (result ScheduleResult, err error) {
2 ...
3 feasibleNodes, diagnosis, err := sched.findNodesThatFitPod(ctx, fwk, state, pod)
4 if err != nil {
5 return result, err
6 }
7
8 ...
9 if len(feasibleNodes) == 1 {
10 return ScheduleResult{
11 SuggestedHost: feasibleNodes[0].Node().Name,
12 EvaluatedNodes: 1 + len(diagnosis.NodeToStatusMap),
13 FeasibleNodes: 1,
14 }, nil
15 }
16
17 priorityList, err := sched.prioritizeNodes(ctx, fwk, state, pod, feasibleNodes)
18 if err != nil {
19 return result, err
20 }
21
22 host, _, err := selectHost(priorityList, numberOfHighestScoredNodesToReport)
23 ...
24
25 return ScheduleResult{
26 SuggestedHost: host,
27 EvaluatedNodes: len(feasibleNodes) + len(diagnosis.NodeToStatusMap),
28 FeasibleNodes: len(feasibleNodes),
29 }, err
获得调度结果 scheduleResult 后,在 sched.schedulingCycle 中的 sched.assume 将 assumePod 的 NodeName 更新为调度的节点 host,并且将 assumePod 添加到缓存中。缓存允许运行假定的操作,该操作将 Pod 临时存储在缓存中,使得 Pod 看起来像已经在快照的所有消费者的指定节点上运行那样。假定操作忽视了 kube-apiserver 和 Pod 实际更新的时间,从而增加调度器的吞吐量。
1func (sched *Scheduler) assume(logger klog.Logger, assumed *v1.Pod, host string) error {
2 assumed.Spec.NodeName = host
3
4 if err := sched.Cache.AssumePod(logger, assumed); err != nil {
5 logger.Error(err, "Scheduler cache AssumePod failed")
6 return err
7 }
8 ...
9 return nil
10}
11
12// kubernetes/pkg/scheduler/internal/cache/cache.go
13func (cache *cacheImpl) AssumePod(logger klog.Logger, pod *v1.Pod) error {
14 ...
15 return cache.addPod(logger, pod, true)
16}
继续如 调度框架 所示,在 sched.schedulingCycle 中执行 Reserve 和 Permit 插件,插件执行通过后调度周期返回 Pod 的调度结果。
接着,进入绑定周期。
绑定周期
绑定周期是一个异步的 goroutine,负责将调度到节点的 Pod 发送给 kube-apiserver。进入绑定周期查看绑定逻辑的实现。
1// kubernetes/pkg/scheduler/schedule_one.go
2func (sched *Scheduler) scheduleOne(ctx context.Context) {
3 ...
4 // 调度周期返回调度结果
5 scheduleResult, assumedPodInfo, status := sched.schedulingCycle(schedulingCycleCtx, state, fwk, podInfo, start, podsToActivate)
6 if !status.IsSuccess() {
7 sched.FailureHandler(schedulingCycleCtx, fwk, assumedPodInfo, status, scheduleResult.nominatingInfo, start)
8 return
9 }
10
11 // 绑定周期绑定调度结果
12 go func() {
13 ...
14 status := sched.bindingCycle(bindingCycleCtx, state, fwk, scheduleResult, assumedPodInfo, start, podsToActivate)
15 if !status.IsSuccess() {
16 sched.handleBindingCycleError(bindingCycleCtx, state, fwk, assumedPodInfo, start, scheduleResult, status)
17 return
18 }
19 ...
20 }()
21}
22
23func (sched *Scheduler) bindingCycle(
24 ctx context.Context,
25 state *framework.CycleState,
26 fwk framework.Framework,
27 scheduleResult ScheduleResult,
28 assumedPodInfo *framework.QueuedPodInfo,
29 start time.Time,
30 podsToActivate *framework.PodsToActivate) *framework.Status {
31 ...
32 // 运行 Permit 插件
33 if status := fwk.WaitOnPermit(ctx, assumedPod); !status.IsSuccess() {
34 ...
35 }
36
37 // 运行 PreBind 插件
38 if status := fwk.RunPreBindPlugins(ctx, state, assumedPod, scheduleResult.SuggestedHost); !status.IsSuccess() {
39 ...
40 }
41
42 // 运行 Bind 插件
43 if status := sched.bind(ctx, fwk, assumedPod, scheduleResult.SuggestedHost, state); !status.IsSuccess() {
44 return status
45 }
46
47 // 运行 PostBind 插件
48 fwk.RunPostBindPlugins(ctx, state, assumedPod, scheduleResult.SuggestedHost)
49 ...
50}
可以看到,绑定周期运行一系列插件进行绑定,进入 Bind 插件查看绑定的行为。
1func (sched *Scheduler) bind(ctx context.Context, fwk framework.Framework, assumed *v1.Pod, targetNode string, state *framework.CycleState) (status *framework.Status) {
2 ...
3 return fwk.RunBindPlugins(ctx, state, assumed, targetNode)
4}
5
6// kubernetes/pkg/scheduler/framework/runtime/framework.go
7func (f *frameworkImpl) RunBindPlugins(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeName string) (status *framework.Status) {
8 ...
9 for _, pl := range f.bindPlugins {
10 status = f.runBindPlugin(ctx, pl, state, pod, nodeName)
11 if status.IsSkip() {
12 continue
13 }
14 ...
15 }
16 ...
17}
18
19func (f *frameworkImpl) runBindPlugin(ctx context.Context, bp framework.BindPlugin, state *framework.CycleState, pod *v1.Pod, nodeName string) *framework.Status {
20 ...
21 status := bp.Bind(ctx, state, pod, nodeName)
22 ...
23 return status
24}
25
26// kubernetes/pkg/scheduler/plugins/defaultbinder/default_binder.go
27func (b DefaultBinder) Bind(ctx context.Context, state *framework.CycleState, p *v1.Pod, nodeName string) *framework.Status {
28 ...
29 logger.V(3).Info("Attempting to bind pod to node", "pod", klog.KObj(p), "node", klog.KRef("", nodeName))
30 binding := &v1.Binding{
31 ObjectMeta: metav1.ObjectMeta{Namespace: p.Namespace, Name: p.Name, UID: p.UID},
32 Target: v1.ObjectReference{Kind: "Node", Name: nodeName},
33 }
34 err := b.handle.ClientSet().CoreV1().Pods(binding.Namespace).Bind(ctx, binding, metav1.CreateOptions{})
35 if err != nil {
36 return framework.AsStatus(err)
37 }
38 return nil
39}
在 Bind 插件中调用 ClientSet 的 Bind 方法将 Pod 和 node 绑定的结果发给 kube-apiserver,实现绑定操作。
总结
本文从源码角度分析了 kube-scheduler 的调度流程,力图做到知其然知其所以然。