前言
在 Kubernetes 架构中,controller manager 是一个永不休止的控制回路组件,其负责控制集群资源的状态。通过监控 kube-apiserver 的资源状态,比较当前资源状态和期望状态,如果不一致,更新 kube-apiserver 的资源状态以保持当前资源状态和期望状态一致。
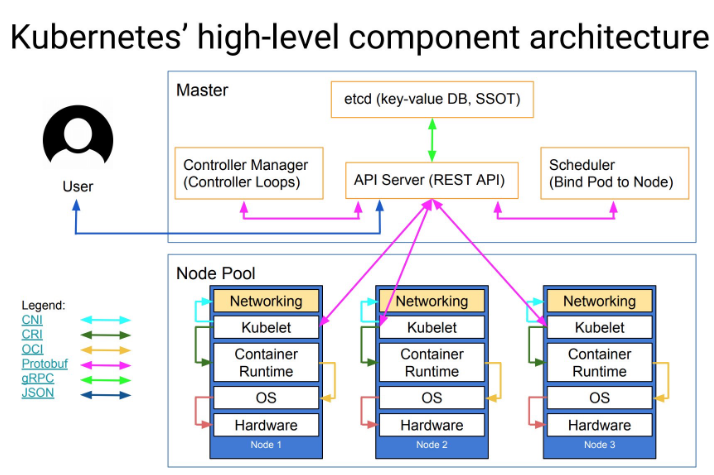
kube-controller-manager
下面从源码角度分析 kube-controller-manager 的工作方式。
kube-controller-manager 使用 Cobra 作为应用命令行框架,和 kube-scheduler,kube-apiserver 初始化过程类似,其流程如下:
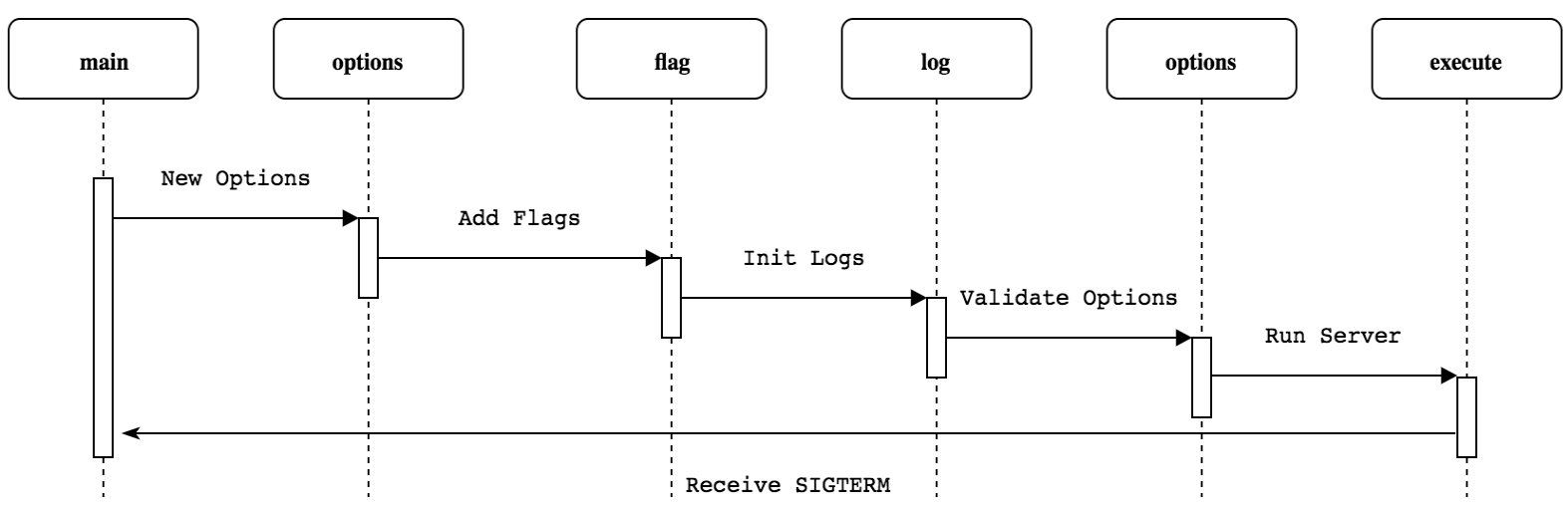
这里,简要给出初始化代码示例:
1# kubernetes/cmd/kube-controller-manager/app/controllermanager.go
2func NewControllerManagerCommand() *cobra.Command {
3 // 创建选项
4 s, err := options.NewKubeControllerManagerOptions()
5 ...
6 cmd := &cobra.Command{
7 ...
8 RunE: func(cmd *cobra.Command, args []string) error {
9 ...
10 // 根据选项,创建配置
11 c, err := s.Config(KnownControllers(), ControllersDisabledByDefault(), ControllerAliases())
12 if err != nil {
13 return err
14 }
15 ...
16 return Run(context.Background(), c.Complete())
17 },
18 ...
19 }
20 ...
21}
进入 Run 函数,看 kube-controller-manager 是怎么运行的。
1# kubernetes/cmd/kube-controller-manager/app/controllermanager.go
2func Run(ctx context.Context, c *config.CompletedConfig) error {
3 ...
4 run := func(ctx context.Context, controllerDescriptors map[string]*ControllerDescriptor) {
5 // 创建上下文
6 controllerContext, err := CreateControllerContext(logger, c, rootClientBuilder, clientBuilder, ctx.Done())
7 if err != nil {
8 logger.Error(err, "Error building controller context")
9 klog.FlushAndExit(klog.ExitFlushTimeout, 1)
10 }
11
12 // 开始控制器,这是主运行逻辑
13 if err := StartControllers(ctx, controllerContext, controllerDescriptors, unsecuredMux, healthzHandler); err != nil {
14 logger.Error(err, "Error starting controllers")
15 klog.FlushAndExit(klog.ExitFlushTimeout, 1)
16 }
17
18 // 启动 informer
19 controllerContext.InformerFactory.Start(stopCh)
20 controllerContext.ObjectOrMetadataInformerFactory.Start(stopCh)
21 close(controllerContext.InformersStarted)
22
23 <-ctx.Done()
24 }
25
26 // No leader election, run directly
27 if !c.ComponentConfig.Generic.LeaderElection.LeaderElect {
28 // 创建控制器描述符
29 controllerDescriptors := NewControllerDescriptors()
30 controllerDescriptors[names.ServiceAccountTokenController] = saTokenControllerDescriptor
31 run(ctx, controllerDescriptors)
32 return nil
33 }
34 ...
35}
和 kube-scheduler 类似,kube-controller-manager 也是多副本单实例运行的组件,需要 leader election 作为 leader 组件运行。这里不过多介绍,具体可参考 Kubernetes leader election 源码分析。
运行控制器管理器。首先,在 NewControllerDescriptors 中注册资源控制器的描述符。
1# kubernetes/cmd/kube-controller-manager/app/controllermanager.go
2func NewControllerDescriptors() map[string]*ControllerDescriptor {
3 register := func(controllerDesc *ControllerDescriptor) {
4 ...
5 controllers[name] = controllerDesc
6 }
7
8 ...
9 // register 函数注册资源控制器
10 register(newEndpointsControllerDescriptor())
11 register(newEndpointSliceControllerDescriptor())
12 register(newEndpointSliceMirroringControllerDescriptor())
13 register(newReplicationControllerDescriptor())
14 register(newPodGarbageCollectorControllerDescriptor())
15 register(newResourceQuotaControllerDescriptor())
16 ...
17
18 return controllers
19}
20
21# kubernetes/cmd/kube-controller-manager/app/apps.go
22func newReplicaSetControllerDescriptor() *ControllerDescriptor {
23 return &ControllerDescriptor{
24 name: names.ReplicaSetController,
25 aliases: []string{"replicaset"},
26 initFunc: startReplicaSetController,
27 }
28}
每个资源控制器描述符包括 initFunc 和启动控制器函数的映射。
在 run 中 StartControllers 运行控制器。
1# kubernetes/cmd/kube-controller-manager/app/controllermanager.go
2func StartControllers(ctx context.Context, controllerCtx ControllerContext, controllerDescriptors map[string]*ControllerDescriptor,
3 unsecuredMux *mux.PathRecorderMux, healthzHandler *controllerhealthz.MutableHealthzHandler) error {
4 ...
5 // 遍历获取资源控制器描述符
6 for _, controllerDesc := range controllerDescriptors {
7 if controllerDesc.RequiresSpecialHandling() {
8 continue
9 }
10
11 // 运行资源控制器
12 check, err := StartController(ctx, controllerCtx, controllerDesc, unsecuredMux)
13 if err != nil {
14 return err
15 }
16 if check != nil {
17 // HealthChecker should be present when controller has started
18 controllerChecks = append(controllerChecks, check)
19 }
20 }
21
22 ...
23 return nil
24}
25
26func StartController(ctx context.Context, controllerCtx ControllerContext, controllerDescriptor *ControllerDescriptor,
27 unsecuredMux *mux.PathRecorderMux) (healthz.HealthChecker, error) {
28 ...
29 // 获取资源控制器描述符的启动函数
30 initFunc := controllerDescriptor.GetInitFunc()
31
32 // 启动资源控制器
33 ctrl, started, err := initFunc(klog.NewContext(ctx, klog.LoggerWithName(logger, controllerName)), controllerCtx, controllerName)
34 if err != nil {
35 logger.Error(err, "Error starting controller", "controller", controllerName)
36 return nil, err
37 }
38 ...
39}
kubernetes 有多个控制器,这里以 Replicaset 控制器为例,介绍控制器是怎么运行的。
进入 Replicaset 控制器的 initFunc 函数运行控制器。
1# kubernetes/cmd/kube-controller-manager/app/apps.go
2func startReplicaSetController(ctx context.Context, controllerContext ControllerContext, controllerName string) (controller.Interface, bool, error) {
3 go replicaset.NewReplicaSetController(
4 klog.FromContext(ctx),
5 controllerContext.InformerFactory.Apps().V1().ReplicaSets(),
6 controllerContext.InformerFactory.Core().V1().Pods(),
7 controllerContext.ClientBuilder.ClientOrDie("replicaset-controller"),
8 replicaset.BurstReplicas,
9 ).Run(ctx, int(controllerContext.ComponentConfig.ReplicaSetController.ConcurrentRSSyncs))
10 return nil, true, nil
11}
运行 initFunc 实际上运行的是 startReplicaSetController。startReplicaSetController 启动一个 goroutine 运行 replicaset.NewReplicaSetController 和 ReplicaSetController.Run,replicaset.NewReplicaSetController 创建了 informer 的 Eventhandler,ReplicaSetController.Run 负责对 EventHandler 中加入队列的资源做处理。示意图如下:
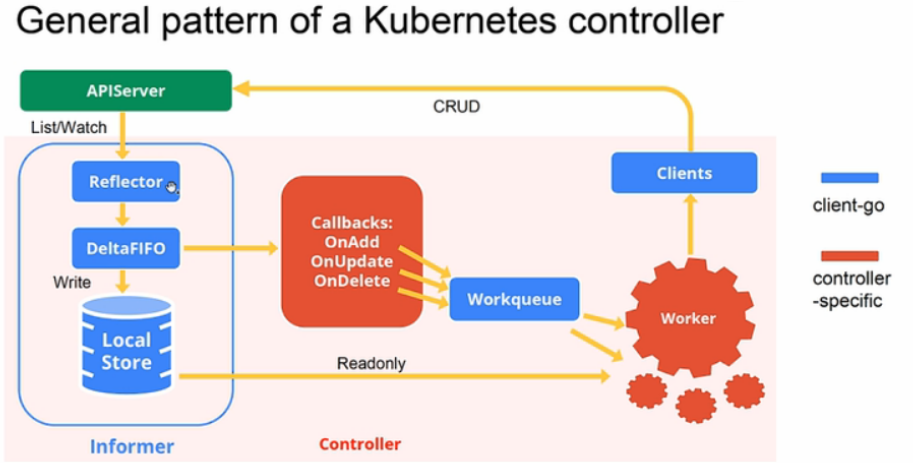
首先,进入 replicaset.NewReplicaSetController 查看函数做了什么。
1# kubernetes/pkg/controller/replicaset/replica_set.go
2func NewReplicaSetController(logger klog.Logger, rsInformer appsinformers.ReplicaSetInformer, podInformer coreinformers.PodInformer, kubeClient clientset.Interface, burstReplicas int) *ReplicaSetController {
3 ...
4 return NewBaseController(logger, rsInformer, podInformer, kubeClient, burstReplicas,
5 apps.SchemeGroupVersion.WithKind("ReplicaSet"),
6 "replicaset_controller",
7 "replicaset",
8 controller.RealPodControl{
9 KubeClient: kubeClient,
10 Recorder: eventBroadcaster.NewRecorder(scheme.Scheme, v1.EventSource{Component: "replicaset-controller"}),
11 },
12 eventBroadcaster,
13 )
14}
15
16func NewBaseController(logger klog.Logger, rsInformer appsinformers.ReplicaSetInformer, podInformer coreinformers.PodInformer, kubeClient clientset.Interface, burstReplicas int,
17 gvk schema.GroupVersionKind, metricOwnerName, queueName string, podControl controller.PodControlInterface, eventBroadcaster record.EventBroadcaster) *ReplicaSetController {
18
19 rsc := &ReplicaSetController{
20 GroupVersionKind: gvk,
21 kubeClient: kubeClient,
22 podControl: podControl,
23 eventBroadcaster: eventBroadcaster,
24 burstReplicas: burstReplicas,
25 expectations: controller.NewUIDTrackingControllerExpectations(controller.NewControllerExpectations()),
26 queue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), queueName),
27 }
28
29 rsInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
30 AddFunc: func(obj interface{}) {
31 rsc.addRS(logger, obj)
32 },
33 UpdateFunc: func(oldObj, newObj interface{}) {
34 rsc.updateRS(logger, oldObj, newObj)
35 },
36 DeleteFunc: func(obj interface{}) {
37 rsc.deleteRS(logger, obj)
38 },
39 })
40 ...
41
42 podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
43 AddFunc: func(obj interface{}) {
44 rsc.addPod(logger, obj)
45 },
46 UpdateFunc: func(oldObj, newObj interface{}) {
47 rsc.updatePod(logger, oldObj, newObj)
48 },
49 DeleteFunc: func(obj interface{}) {
50 rsc.deletePod(logger, obj)
51 },
52 })
53 ...
54
55 rsc.syncHandler = rsc.syncReplicaSet
56
57 return rsc
58}
函数定义了 ReplicaSetController 和 podInformer,负责监控 kube-apiserver 中 ReplicaSet 和 Pod 的变化,根据资源的不同变动触发对应的 Event Handler。
接着,进入 Run 查看函数做了什么。
1# kubernetes/pkg/controller/replicaset/replica_set.go
2func (rsc *ReplicaSetController) Run(ctx context.Context, workers int) {
3 ...
4 // 同步缓存和 kube-apiserver 中获取的资源
5 if !cache.WaitForNamedCacheSync(rsc.Kind, ctx.Done(), rsc.podListerSynced, rsc.rsListerSynced) {
6 return
7 }
8
9 for i := 0; i < workers; i++ {
10 // worker 负责处理队列中的资源
11 go wait.UntilWithContext(ctx, rsc.worker, time.Second)
12 }
13
14 <-ctx.Done()
15}
16
17func (rsc *ReplicaSetController) worker(ctx context.Context) {
18 // worker 是永不停止的
19 for rsc.processNextWorkItem(ctx) {
20 }
21}
22
23func (rsc *ReplicaSetController) processNextWorkItem(ctx context.Context) bool {
24 // 读取队列中的资源
25 key, quit := rsc.queue.Get()
26 if quit {
27 return false
28 }
29 defer rsc.queue.Done(key)
30
31 // 处理队列中的资源
32 err := rsc.syncHandler(ctx, key.(string))
33 if err == nil {
34 rsc.queue.Forget(key)
35 return true
36 }
37
38 ...
39 return true
40}
可以看到,rsc.syncHandler 处理队列中的资源,rsc.syncHandler 实际执行的是 ReplicaSetController.syncReplicaSet。
理清了代码的结构,我们以一个删除 Pod 示例看 kube-controller-manager 是怎么运行的。
删除 Pod 示例
示例条件
创建 Replicaset 如下:
1# helm list
2NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
3test default 1 2024-02-29 16:24:43.896757193 +0800 CST deployed test-0.1.0 1.16.0
4
5# kubectl get replicaset
6NAME DESIRED CURRENT READY AGE
7test-6d47479b6b 1 1 1 10d
8
9# kubectl get pods
10NAME READY STATUS RESTARTS AGE
11test-6d47479b6b-5k6cb 1/1 Running 0 9d
删除 pod 查看 kube-controller-manager 是怎么运行的。
运行流程
删除 pod:
1# kubectl delete pods test-6d47479b6b-5k6cb
删除 pod 后,podInformer 的 Event handler 接受到 pod 的变化,调用 ReplicaSetController.deletePod 函数:
1func (rsc *ReplicaSetController) deletePod(logger klog.Logger, obj interface{}) {
2 pod, ok := obj.(*v1.Pod)
3
4 ...
5 logger.V(4).Info("Pod deleted", "delete_by", utilruntime.GetCaller(), "deletion_timestamp", pod.DeletionTimestamp, "pod", klog.KObj(pod))
6 ...
7 rsc.queue.Add(rsKey)
8}
ReplicaSetController.deletePod 将删除的 pod 加入到队列中。接着,worker 中的 ReplicaSetController.processNextWorkItem 从队列中获取删除的 pod,进入 ReplicaSetController.syncReplicaSet 处理。
1func (rsc *ReplicaSetController) syncReplicaSet(ctx context.Context, key string) error {
2 ...
3 namespace, name, err := cache.SplitMetaNamespaceKey(key)
4 ...
5
6 // 获取 pod 对应的 replicaset
7 rs, err := rsc.rsLister.ReplicaSets(namespace).Get(name)
8 ...
9
10 // 获取所有 pod
11 allPods, err := rsc.podLister.Pods(rs.Namespace).List(labels.Everything())
12 if err != nil {
13 return err
14 }
15
16 // Ignore inactive pods.
17 filteredPods := controller.FilterActivePods(logger, allPods)
18
19 // 获取 replicaset 下的 pod
20 // 这里 pod 被删掉了,filteredPods 为 0
21 filteredPods, err = rsc.claimPods(ctx, rs, selector, filteredPods)
22 if err != nil {
23 return err
24 }
25
26 // replicaset 下的 pod 被删除
27 // 进入 rsc.manageReplicas
28 var manageReplicasErr error
29 if rsNeedsSync && rs.DeletionTimestamp == nil {
30 manageReplicasErr = rsc.manageReplicas(ctx, filteredPods, rs)
31 }
32 ...
33}
继续进入 ReplicaSetController.manageReplicas:
1func (rsc *ReplicaSetController) manageReplicas(ctx context.Context, filteredPods []*v1.Pod, rs *apps.ReplicaSet) error {
2 diff := len(filteredPods) - int(*(rs.Spec.Replicas))
3 ...
4 if diff < 0 {
5 logger.V(2).Info("Too few replicas", "replicaSet", klog.KObj(rs), "need", *(rs.Spec.Replicas), "creating", diff)
6 ...
7 successfulCreations, err := slowStartBatch(diff, controller.SlowStartInitialBatchSize, func() error {
8 err := rsc.podControl.CreatePods(ctx, rs.Namespace, &rs.Spec.Template, rs, metav1.NewControllerRef(rs, rsc.GroupVersionKind))
9 if err != nil {
10 if apierrors.HasStatusCause(err, v1.NamespaceTerminatingCause) {
11 // if the namespace is being terminated, we don't have to do
12 // anything because any creation will fail
13 return nil
14 }
15 }
16 return err
17 })
18 ...
19 }
20 ...
21}
当 filteredPods 小于 Replicaset 中 spec 域定义的 Replicas 时,进入 rsc.podControl.CreatePods 创建 pod:
1func (r RealPodControl) CreatePods(ctx context.Context, namespace string, template *v1.PodTemplateSpec, controllerObject runtime.Object, controllerRef *metav1.OwnerReference) error {
2 return r.CreatePodsWithGenerateName(ctx, namespace, template, controllerObject, controllerRef, "")
3}
4
5func (r RealPodControl) CreatePodsWithGenerateName(ctx context.Context, namespace string, template *v1.PodTemplateSpec, controllerObject runtime.Object, controllerRef *metav1.OwnerReference, generateName string) error {
6 ...
7 return r.createPods(ctx, namespace, pod, controllerObject)
8}
9
10func (r RealPodControl) createPods(ctx context.Context, namespace string, pod *v1.Pod, object runtime.Object) error {
11 ...
12 newPod, err := r.KubeClient.CoreV1().Pods(namespace).Create(ctx, pod, metav1.CreateOptions{})
13 ...
14 logger.V(4).Info("Controller created pod", "controller", accessor.GetName(), "pod", klog.KObj(newPod))
15 ...
16
17 return nil
18}
接着,回到 ReplicaSetController.syncReplicaSet:
1func (rsc *ReplicaSetController) syncReplicaSet(ctx context.Context, key string) error {
2 ...
3 newStatus := calculateStatus(rs, filteredPods, manageReplicasErr)
4 updatedRS, err := updateReplicaSetStatus(logger, rsc.kubeClient.AppsV1().ReplicaSets(rs.Namespace), rs, newStatus)
5 if err != nil {
6 return err
7 }
8 ...
9}
虽然 pod 重建过,不过这里的 filteredPods 是 0,updateReplicaSetStatus 会更新 Replicaset 的当前状态为 0。
更新了 Replicaset 的状态又会触发 Replicaset 的 Event Handler,从而再次进入 ReplicaSetController.syncReplicaSet。这时,如果 pod 重建完成,filteredPods 将过滤出重建的 pod,调用 updateReplicaSetStatus 更新 Replicaset 的当前状态到期望状态。
小结
本文介绍了 kube-controller-manager 的运行流程,并且从一个删除 pod 的示例入手,看 kube-controller-manager 是如何控制资源状态的。