概述
在使用 Go 开发时几乎都会用到 net/http 标准库。但是,对库的内部实现不了解,仅限于会用。遇到问题容易懵,比如:
- 长连接和短连接有什么区别?具体什么实现原理?
net/http如何处理并发请求?net/http有用到缓存吗?缓存用来干什么?- ……
单个问题各个击破,不如深入梳理下 net/http 标准库一网打尽。本文将深入学习 net/http 标准库,力图做到知其然知其所以然。
服务端
源码走读
先看一段服务端示例代码:
1func helloHandler(w http.ResponseWriter, r *http.Request) {
2 // 向客户端写入响应内容
3 fmt.Fprint(w, "Hello I am server 3")
4}
5
6func main() {
7 // 创建自定义的ServeMux实例
8 mux := http.NewServeMux()
9
10 // 在mux上注册路由和处理函数
11 mux.HandleFunc("/", helloHandler)
12
13 // 启动服务器并监听12302端口,使用自定义的mux作为handler
14 fmt.Println("Server is listening on port 12302...")
15 if err := http.ListenAndServe(":12302", mux); err != nil {
16 // 错误处理
17 fmt.Printf("Failed to start server: %v\n", err)
18 }
19}
示例中有几类概念需要介绍。
多路复用器 http.ServeMux
1type ServeMux struct {
2 mu sync.RWMutex // 多路复用器锁
3 tree routingNode // 路由节点,用来存储路由 pattern 和对应的 handler
4 ...
5}
路由处理器 handler
handler 是一个实现 func(ResponseWriter, *Request) 函数接口的函数,用来处理请求。
流程
服务端启动需要经过以下流程。
1) 创建多路复用器
创建自定义 http.ServeMux 多路复用器,如果不创建的话,则会使用默认 http.DefaultServeMux 多路复用器:
1// NewServeMux allocates and returns a new [ServeMux].
2func NewServeMux() *ServeMux {
3 return &ServeMux{}
4}
5
6var DefaultServeMux = &defaultServeMux
7
8var defaultServeMux ServeMux
2) 注册路由处理器
调用多路复用器的 HandleFunc 方法注册路由处理器:
1func (mux *ServeMux) HandleFunc(pattern string, handler func(ResponseWriter, *Request)) {
2 if use121 {
3 mux.mux121.handleFunc(pattern, handler)
4 } else {
5 // 将 pattern 和路由处理器注册到多路复用器
6 mux.register(pattern, HandlerFunc(handler))
7 }
8}
注册的过程实际是将 pattern 和 handler 的映射关系写入 ServeMux.tree 中。可以根据请求的 pattern 从 ServeMux.tree 中获取对应的 handler。
3)监听服务
调用 http.ListenAndServe 监听服务:
1func ListenAndServe(addr string, handler Handler) error {
2 server := &Server{Addr: addr, Handler: handler}
3 return server.ListenAndServe()
4}
5
6func (s *Server) ListenAndServe() error {
7 ...
8 // 调用 net.Listen 获取 listener
9 ln, err := net.Listen("tcp", addr)
10 if err != nil {
11 return err
12 }
13 return s.Serve(ln)
14}
15
16func (s *Server) Serve(l net.Listener) error {
17 ...
18 for {
19 // Accept waits for and returns the next connection to the listener.
20 rw, err := l.Accept()
21 ...
22 c := s.newConn(rw)
23 // 异步启动协程处理请求
24 go c.serve(connCtx)
25 }
26}
监听服务监听到请求后会异步调用 conn.serve 启动协程处理请求:
1func (c *conn) serve(ctx context.Context) {
2 for {
3 // 读请求
4 w, err := c.readRequest(ctx)
5 ...
6 // 调用多路复用器的 ServeHTTP 方法处理请求
7 serverHandler{c.server}.ServeHTTP(w, w.req)
8 ...
9}
10
11func (sh serverHandler) ServeHTTP(rw ResponseWriter, req *Request) {
12 // 如果多路复用器为空,则用默认多路复用器
13 handler := sh.srv.Handler
14 if handler == nil {
15 handler = DefaultServeMux
16 }
17 ...
18
19 handler.ServeHTTP(rw, req)
20}
21
22func (mux *ServeMux) ServeHTTP(w ResponseWriter, r *Request) {
23 ...
24 var h Handler
25 if use121 {
26 h, _ = mux.mux121.findHandler(r)
27 } else {
28 // 根据请求从多路复用器找到请求 pattern 对应的路由处理器
29 h, r.Pattern, r.pat, r.matches = mux.findHandler(r)
30 }
31
32 // 调用路由处理器的 ServeHTTP 方法处理请求
33 h.ServeHTTP(w, r)
34}
服务端的处理流程并不复杂,主要是注册路由处理器和回调路由处理器过程,流程图就不画了,接下来介绍客户端的处理逻辑,这是比较复杂的部分。
客户端
核心数据结构
Client
1type Client struct {
2 // 通信模块,负责和服务端建立通信
3 Transport RoundTripper
4
5 // Cookie 模块,负责管理 Cookie
6 Jar CookieJar
7
8 // 超时时间,这个时间是请求处理的总超时时间
9 Timeout time.Duration
RoundTripper
1type RoundTripper interface {
2 RoundTrip(*Request) (*Response, error)
3}
RoundTripper 是通信模块的 interface,需要实现方法 Roundtrip。通过传入请求 Request,与服务端交互后获得响应 Response。
1type Transport struct {
2 idleMu sync.Mutex
3 ...
4 // 空闲连接,实现复用,每个连接只能被一个请求使用
5 idleConn map[connectMethodKey][]*persistConn
6 // 等待连接队列,需要等待的连接请求会放到 idleConnWait 中
7 idleConnWait map[connectMethodKey]wantConnQueue
8 // 空闲连接 lru,结合 idleConn 根据连接时间管理连接
9 idleLRU connLRU
10
11 // 建立长连接开关,如果为 true 则不复用连接
12 DisableKeepAlives bool
Transport 是实现了 RoundTripper 接口的方法,是用于通信的模块。
源码走读
客户端请求的示例如下:
1func main() {
2 resp, err := client.Get("http://localhost:12302/")
3 if err != nil {
4 // 错误处理
5 fmt.Printf("Failed to send request: %v\n", err)
6 return
7 }
8
9 // 读取响应体内容
10 body, err := io.ReadAll(resp.Body)
11 if err != nil {
12 // 错误处理
13 fmt.Printf("Failed to read response body: %v\n", err)
14 return
15 }
16
17 // 打印服务器返回的响应内容
18 fmt.Printf("Server response: %s\n", body)
19 if err := resp.Body.Close(); err != nil {
20 fmt.Printf("Failed to close response body: %v\n", err)
21 }
22}
请求服务端
client.Get 调用 api 请求服务端,获取响应。
1func (c *Client) Get(url string) (resp *Response, err error) {
2 // 构造请求体 request
3 req, err := NewRequest("GET", url, nil)
4 if err != nil {
5 return nil, err
6 }
7
8 // 调用 client.Do(req) 获取响应
9 return c.Do(req)
10}
11
12func (c *Client) Do(req *Request) (*Response, error) {
13 return c.do(req)
14}
15
16func (c *Client) do(req *Request) (retres *Response, reterr error) {
17 ...
18 for {
19 ...
20 // 调用 client.send() 获取响应
21 if resp, didTimeout, err = c.send(req, deadline); err != nil {
22 ...
23 }
24 ...
25}
客户端调用 client.send() 发送请求到服务端,获取响应。
1func (c *Client) send(req *Request, deadline time.Time) (resp *Response, didTimeout func() bool, err error) {
2 ...
3 resp, didTimeout, err = send(req, c.transport(), deadline)
4 if err != nil {
5 return nil, didTimeout, err
6 }
7 ...
8 return resp, nil, nil
9}
10
11func send(ireq *Request, rt RoundTripper, deadline time.Time) (resp *Response, didTimeout func() bool, err error) {
12 ...
13 // 通信模块 Transport.RoundTrip
14 resp, err = rt.RoundTrip(req)
15 if err != nil {
16 ...
17 }
18 ...
19}
通信模块 Transport 开始接管通信过程。
1func (t *Transport) RoundTrip(req *Request) (*Response, error) {
2 return t.roundTrip(req)
3}
4
5func (t *Transport) roundTrip(req *Request) (_ *Response, err error) {
6 ...
7 // 获取连接
8 pconn, err := t.getConn(treq, cm)
9
10 var resp *Response
11 if pconn.alt != nil {
12 // HTTP/2 path.
13 resp, err = pconn.alt.RoundTrip(req)
14 } else {
15 // 调用连接的 roundTrip 方法获取服务端响应
16 resp, err = pconn.roundTrip(treq)
17 }
18 ...
19}
Transport.roundTrip 方法是这里的重点。主要包括两大逻辑:
- 调用
Transport.getConn获取连接; - 调用连接的
roundTrip方法获取响应;
获取连接
1func (t *Transport) getConn(treq *transportRequest, cm connectMethod) (_ *persistConn, err error) {
2 ...
3 // 构造连接请求对象 wantConn
4 w := &wantConn{
5 cm: cm,
6 key: cm.key(),
7 ctx: dialCtx,
8 cancelCtx: dialCancel,
9 result: make(chan connOrError, 1),
10 beforeDial: testHookPrePendingDial,
11 afterDial: testHookPostPendingDial,
12 }
13 defer func() {
14 if err != nil {
15 w.cancel(t, err)
16 }
17 }()
18
19 // 获取连接
20 if delivered := t.queueForIdleConn(w); !delivered {
21 t.queueForDial(w)
22 }
23
24 // 异步获取结果并处理 context
25 select {
26 case r := <-w.result:
27 ...
28 return r.pc, r.err
29 case <-treq.ctx.Done():
30 ...
31 }
32}
Transport.getConn 首先构造连接请求对象 wantConn,然后根据 wantConn 调用 Transport.queueForIdleConn 获取连接。如果获取不到,调用 t.queueForDial 创建连接。
获取连接的过程是异步的,个人理解是创建连接的时间是不确定的,可以根据 context 上下文实现优雅退出,防止阻塞。
1func (t *Transport) queueForIdleConn(w *wantConn) (delivered bool) {
2 // 如果 disable keep alive 则返回
3 if t.DisableKeepAlives {
4 return false
5 }
6
7 ...
8 // 判断连接是否存在于 Transport 中
9 // 如果存在则复用连接,如果不存在则创建连接
10 if list, ok := t.idleConn[w.key]; ok {
11 stop := false
12 delivered := false
13 for len(list) > 0 && !stop {
14 // 复用连接
15 pconn := list[len(list)-1]
16 ...
17 delivered = w.tryDeliver(pconn, nil, pconn.idleAt)
18 if delivered {
19 ...
20 }
21 }
22
23 // 更新 Transport.idleConn
24 // 同一个连接不能被多个请求使用,所以这里要删除 idleConn 中的连接
25 if len(list) > 0 {
26 t.idleConn[w.key] = list
27 } else {
28 delete(t.idleConn, w.key)
29 }
30 if stop {
31 return delivered
32 }
33 }
34
35 // 连接不存在于 Transport.idleConn 中
36 // 将 wantConn 加入到 Transport.idleConnWait 队列中,等待连接
37 if t.idleConnWait == nil {
38 t.idleConnWait = make(map[connectMethodKey]wantConnQueue)
39 }
40 q := t.idleConnWait[w.key]
41 q.cleanFrontNotWaiting()
42 q.pushBack(w)
43 t.idleConnWait[w.key] = q
44 return false
45}
Transport.queueForIdleConn 判断 Transport.idleConn 是否有空闲连接,如果有则调用 wantConn.tryDeliver 传递连接:
1func (w *wantConn) tryDeliver(pc *persistConn, err error, idleAt time.Time) bool {
2 w.mu.Lock()
3 defer w.mu.Unlock()
4 ...
5 // 实际是往 wantConn.result 通道中写 connOrError 对象,该对象中包括连接 pc
6 w.result <- connOrError{pc: pc, err: err, idleAt: idleAt}
7 close(w.result)
8
9 return true
10}
如果 Transport.idleConn 没有连接,则将 wantConn 加入等待队列 Transport.idleConnWait。然后调用 Transport.queueForDial 创建连接。
1func (t *Transport) queueForDial(w *wantConn) {
2 ...
3 // 判断连接请求是否达到 Transport.connsPerHost 上限
4 if n := t.connsPerHost[w.key]; n < t.MaxConnsPerHost {
5 if t.connsPerHost == nil {
6 t.connsPerHost = make(map[connectMethodKey]int)
7 }
8 t.connsPerHost[w.key] = n + 1
9 // 如果没到请求上限,创建连接
10 t.startDialConnForLocked(w)
11 return
12 }
13 ...
14 // 如果达到请求上限,将请求加入等待队列
15 if t.connsPerHostWait == nil {
16 t.connsPerHostWait = make(map[connectMethodKey]wantConnQueue)
17 }
18 q := t.connsPerHostWait[w.key]
19 q.cleanFrontNotWaiting()
20 q.pushBack(w)
21 t.connsPerHostWait[w.key] = q
22}
Transport.queueForDial 判断连接是否达到 Transport.connsPerHost 上限。如果达到则将连接请求加入等待队列,如果未达到则调用 Transport.startDialConnForLocked 创建连接。
1func (t *Transport) startDialConnForLocked(w *wantConn) {
2 ...
3 go func() {
4 // 调用 Transport.dialConnFor 创建连接
5 t.dialConnFor(w)
6 t.connsPerHostMu.Lock()
7 defer t.connsPerHostMu.Unlock()
8 w.cancelCtx = nil
9 }()
10}
11
12func (t *Transport) dialConnFor(w *wantConn) {
13 ...
14 // 调用 Transport.dialConn 创建连接
15 pc, err := t.dialConn(ctx, w.cm)
16 // deliver 创建的连接
17 delivered := w.tryDeliver(pc, err, time.Time{})
18 ...
19}
Transport.dialConnFor 调用 Transport.dialConn 创建连接,然后 deliver 该连接。
1func (t *Transport) dialConn(ctx context.Context, cm connectMethod) (pconn *persistConn, err error) {
2 pconn = &persistConn{
3 t: t,
4 cacheKey: cm.key(),
5 reqch: make(chan requestAndChan, 1),
6 writech: make(chan writeRequest, 1),
7 closech: make(chan struct{}),
8 writeErrCh: make(chan error, 1),
9 writeLoopDone: make(chan struct{}),
10 }
11
12 if cm.scheme() == "https" && t.hasCustomTLSDialer() {
13 ...
14 } else {
15 // 调用 Transport.dial 创建连接
16 conn, err := t.dial(ctx, "tcp", cm.addr())
17 ...
18 // 将连接赋给 pconn
19 pconn.conn = conn
20 }
21
22 // 将 Reader 和 Writter 赋给 pconn
23 // pconn.br 负责从连接中读服务端的响应,pconn.bw 负责写客户端请求到连接
24 pconn.br = bufio.NewReaderSize(pconn, t.readBufferSize())
25 pconn.bw = bufio.NewWriterSize(persistConnWriter{pconn}, t.writeBufferSize())
26
27 // 异步启动两个伴生协程负责读写连接
28 go pconn.readLoop()
29 go pconn.writeLoop()
30 return pconn, nil
31}
Transport.dialConn 这个方法很重要,它负责创建连接,创建连接的过程实际是和服务端进行三次握手建立 TCP 连接的过程。接着,启动两个伴生协程负责读写连接。
获取到连接后,会用这个连接获取服务端响应。
获取响应
1func (t *Transport) roundTrip(req *Request) (_ *Response, err error) {
2 ...
3 for {
4 // 获取连接
5 pconn, err := t.getConn(treq, cm)
6 ...
7
8 var resp *Response
9 if pconn.alt != nil {
10 // HTTP/2 path.
11 resp, err = pconn.alt.RoundTrip(req)
12 } else {
13 // 通过连接获取响应
14 resp, err = pconn.roundTrip(treq)
15 }
16 }
17 ...
18}
19
20func (pc *persistConn) roundTrip(req *transportRequest) (resp *Response, err error) {
21 ...
22 // 写消息到连接的 writech 通道
23 pc.writech <- writeRequest{req, writeErrCh, continueCh}
24
25 resc := make(chan responseAndError)
26 // 写消息到连接的 reqch 通道
27 pc.reqch <- requestAndChan{
28 treq: req,
29 ch: resc,
30 addedGzip: requestedGzip,
31 continueCh: continueCh,
32 callerGone: gone,
33 }
34
35 // 闭包函数处理响应
36 handleResponse := func(re responseAndError) (*Response, error) {
37 ...
38 return re.res, nil
39 }
40
41 for {
42 select {
43 ...
44 // 监听连接的 reqch.ch 通道
45 case re := <-resc:
46 return handleResponse(re)
47 }
48 }
49}
在获取响应这里将 writeRequest 和 requestAndChan 写入通道 pc.writech 和 pc.reqch 中,接着监听 pc.reqch.ch 通道,如果通道中有数据,则调用 handleResponse 处理响应。
那么,是谁在消费 pc.writech 和 pc.reqch 呢?又是谁在往 pc.reqch.ch 写数据呢?
回答这个问题,需要看读写连接的伴生协程。
读写连接
写协程
1func (pc *persistConn) writeLoop() {
2 defer close(pc.writeLoopDone)
3 for {
4 select {
5 // 监听 pc.writech 通道
6 case wr := <-pc.writech:
7 startBytesWritten := pc.nwrite
8 // 写请求到连接,服务端会从连接中接受到该请求并返回响应
9 err := wr.req.Request.write(pc.bw, pc.isProxy, wr.req.extra, pc.waitForContinue(wr.continueCh))
10 ...
11 pc.writeErrCh <- err // to the body reader, which might recycle us
12 wr.ch <- err // to the roundTrip function
13 if err != nil {
14 pc.close(err)
15 return
16 }
17 // 如果收到关闭请求,则退出写协程
18 case <-pc.closech:
19 return
20 }
21 }
22}
可以看到,写协程主要做了两件事:
- 作为消费者监听
pc.writech通道,将请求写入连接; - 阻塞等待
pc.closech,退出协程;
读协程
读协程负责从连接中读取服务端的响应数据。
1func (pc *persistConn) readLoop() {
2 ...
3 defer func() {
4 pc.close(closeErr)
5 pc.t.removeIdleConn(pc)
6 }()
7 ...
8 alive := true
9 for alive {
10 ...
11 // 阻塞请求通道
12 rc := <-pc.reqch
13 trace := rc.treq.trace
14
15 var resp *Response
16 if err == nil {
17 // 从连接中读响应数据
18 resp, err = pc.readResponse(rc, trace)
19 } else {
20 err = transportReadFromServerError{err}
21 closeErr = err
22 }
23 ...
24 waitForBodyRead := make(chan bool, 2)
25 // 构造 body
26 body := &bodyEOFSignal{
27 body: resp.Body,
28 ...
29 fn: func(err error) error {
30 isEOF := err == io.EOF
31 waitForBodyRead <- isEOF
32 if isEOF {
33 <-eofc // see comment above eofc declaration
34 } else if err != nil {
35 if cerr := pc.canceled(); cerr != nil {
36 return cerr
37 }
38 }
39 return err
40 },
41 }
42
43 // 将构造的 body 赋值到 resp.Body
44 resp.Body = body
45 ...
46 select {
47 // 将响应 resp 传递给 rc.ch 通道
48 case rc.ch <- responseAndError{res: resp}:
49 case <-rc.callerGone:
50 return
51 }
52
53 select {
54 // 阻塞等待
55 case bodyEOF := <-waitForBodyRead:
56 alive = alive &&
57 bodyEOF &&
58 !pc.sawEOF &&
59 pc.wroteRequest() &&
60 tryPutIdleConn(rc.treq)
61 if bodyEOF {
62 eofc <- struct{}{}
63 }
64 case <-rc.treq.ctx.Done():
65 alive = false
66 pc.cancelRequest(context.Cause(rc.treq.ctx))
67 // 退出协程
68 case <-pc.closech:
69 alive = false
70 }
71
72 rc.treq.cancel(errRequestDone)
73 testHookReadLoopBeforeNextRead()
74 }
75}
读协程作为消费者读取 pc.reqch 通道,接着调用 persistConn.readResponse 读取响应。然后,构造响应 body,最后阻塞等待。
至此,基本过完了创建连接,读写连接的逻辑。下面介绍如何复用连接。
复用连接
将视线移到 persistConn.readLoop 构造 body 的逻辑:
1 // 构造 body
2 body := &bodyEOFSignal{
3 body: resp.Body,
4 ...
5 fn: func(err error) error {
6 isEOF := err == io.EOF
7 waitForBodyRead <- isEOF
8 if isEOF {
9 <-eofc // see comment above eofc declaration
10 } else if err != nil {
11 if cerr := pc.canceled(); cerr != nil {
12 return cerr
13 }
14 }
15 return err
16 },
17 }
body.fn 函数会写 isEOF 到 waitForBodyRead 通道,这个通道是读协程在消费:
1func (pc *persistConn) readLoop() {
2 ...
3 for alive {
4 select {
5 // 接收 `waitForBodyRead`
6 case bodyEOF := <-waitForBodyRead:
7 alive = alive &&
8 bodyEOF &&
9 !pc.sawEOF &&
10 pc.wroteRequest() &&
11 // 调用 tryPutIdleConn 将连接加入到空闲队列
12 tryPutIdleConn(rc.treq)
13 if bodyEOF {
14 eofc <- struct{}{}
15 }
16 ...
17 }
18 ...
19}
读协程在收到 waitForBodyRead 通道数据后,会根据一系列判断调用 tryPutIdleConn 将连接加入到 Transport 的空闲队列中。
1func (pc *persistConn) readLoop() {
2 closeErr := errReadLoopExiting // default value, if not changed below
3 defer func() {
4 pc.close(closeErr)
5 pc.t.removeIdleConn(pc)
6 }()
7
8 tryPutIdleConn := func(treq *transportRequest) bool {
9 trace := treq.trace
10 // 调用 pc.t.tryPutIdleConn 添加连接
11 if err := pc.t.tryPutIdleConn(pc); err != nil {
12 ...
13 }
14 ...
15 return true
16 }
17 ...
18}
19
20func (t *Transport) tryPutIdleConn(pconn *persistConn) error {
21 if t.DisableKeepAlives || t.MaxIdleConnsPerHost < 0 {
22 return errKeepAlivesDisabled
23 }
24
25 // 如果连接已经 broken 了,则返回 error
26 if pconn.isBroken() {
27 return errConnBroken
28 }
29
30 // 标记连接是可复用的
31 pconn.markReused()
32
33 // 加锁
34 t.idleMu.Lock()
35 defer t.idleMu.Unlock()
36
37 // 获取连接的 key
38 key := pconn.cacheKey
39 // 判断连接的 key 是否在 Transport.idleConnWait 等待队列
40 // 如果在等待队列中,则 remove 等待队列中的 wantConn
41 if q, ok := t.idleConnWait[key]; ok {
42 // 如果连接在 Transport.idleConnWait 等待队列
43 done := false
44 if pconn.alt == nil {
45 // HTTP/1.
46 // Loop over the waiting list until we find a w that isn't done already, and hand it pconn.
47 for q.len() > 0 {
48 w := q.popFront()
49 if w.tryDeliver(pconn, nil, time.Time{}) {
50 done = true
51 break
52 }
53 }
54 } else {
55 ...
56 }
57 }
58 if q.len() == 0 {
59 delete(t.idleConnWait, key)
60 } else {
61 t.idleConnWait[key] = q
62 }
63 if done {
64 return nil
65 }
66 }
67
68 // 如果空闲队列已经 close 了,退出
69 if t.closeIdle {
70 return errCloseIdle
71 }
72
73 // 如果空闲队列为 nil,初始化空闲队列
74 if t.idleConn == nil {
75 t.idleConn = make(map[connectMethodKey][]*persistConn)
76 }
77
78 // 建立请求和连接的映射存到空闲队列中
79 idles := t.idleConn[key]
80 if len(idles) >= t.maxIdleConnsPerHost() {
81 return errTooManyIdleHost
82 }
83
84 for _, exist := range idles {
85 if exist == pconn {
86 log.Fatalf("dup idle pconn %p in freelist", pconn)
87 }
88 }
89
90 // 将连接加入到空闲队列中
91 t.idleConn[key] = append(idles, pconn)
92
93 // 将连接加入到 lru 缓存,lru 缓存可以用来管理连接
94 t.idleLRU.add(pconn)
95 if t.MaxIdleConns != 0 && t.idleLRU.len() > t.MaxIdleConns {
96 oldest := t.idleLRU.removeOldest()
97 oldest.close(errTooManyIdle)
98 t.removeIdleConnLocked(oldest)
99 }
100
101 ...
102 return nil
103}
在 Transport.tryPutIdleConn 中将连接加入到空闲队列和 LRU 缓存,后续的请求可以从空闲队列中复用连接。过期的连接会从空闲队列和 LRU 缓存移除。
基准测试
我们构造了三种场景用于测试性能:
- 连接池复用连接;
- 连接池不复用连接;
- 客户端复用连接,而服务端关闭连接;
具体代码实现在 这里
测试结果如下:
1 go test -bench=. -benchmem -run=^$
2goos: darwin
3goarch: arm64
4pkg: client
5cpu: Apple M3
6BenchmarkServerClosesConnection-8 21 52007139 ns/op 21505 B/op 139 allocs/op
7BenchmarkWithConnectionPool-8 51 21748487 ns/op 18985 B/op 127 allocs/op
8BenchmarkWithoutConnectionPool-8 10 102032821 ns/op 23189 B/op 140 allocs/op
9PASS
10ok client 3.702s
可以看到,有复用的情况性能最好,无复用的情况性能最差,而客户端复用,服务端关闭连接的情况介于二者之间。个人猜测,虽然连接已经关闭了,但是还是有部分资源是可复用的,相比于无复用性能会好点。
小结
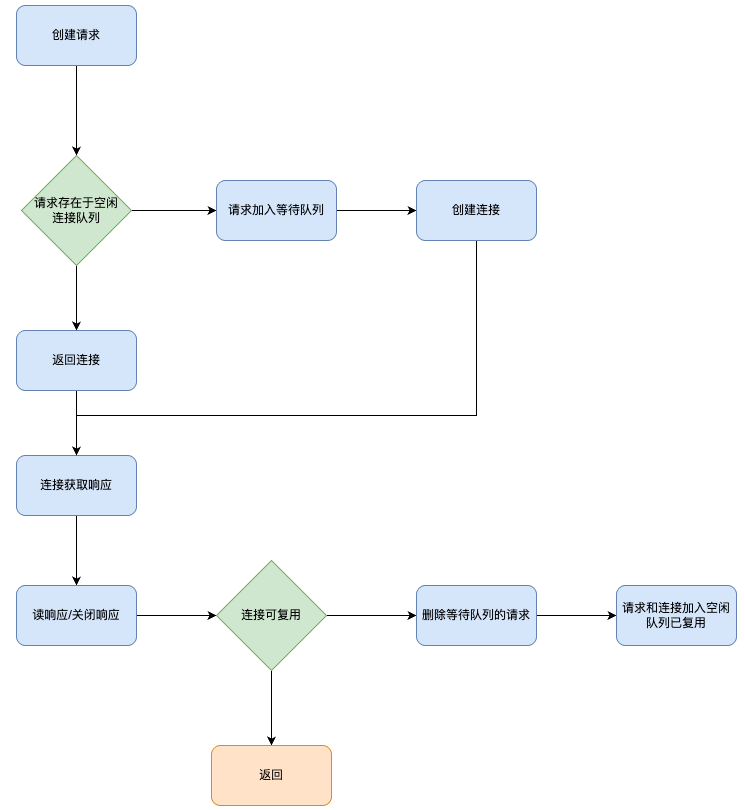
本文介绍了 net/http 标准库的服务端和客户端流程,相比于服务端,客户端要更复杂,大致画出客户端处理流程如下: